

28 Nov 08 Rekursive Funktionen
Wie in der Übung versprochen ein Post über rekursive Funktionen.
Rekursive Funktionen sind Funktionen, die sich selbst aufrufen, und sind besonders in der funktionalen Programmierung das Mittel um Programme zu schreiben, da in der reinen funktionalen Programmierung keine Side Effects existieren.
Man kann generell rekursive Funktionen in zwei Klassen einteilen:
- terminierende rekursive Funktionen
- nicht-terminierende rekursive Funktionen
Wir wollen uns natürlich auf die terminierenden Funktionen beschränken, wobei es unmöglich ist vorab festzustellen, ob eine beliebige Funktion für alle Eingaben terminiert oder nicht (siehe Halte-Problem in der Theoretischen Informatik).
Deswegen möchte ich vorstellen, wie wir rekursive Funktionen schreiben können, die auch sicher terminieren und das machen, was wir wollen.
An sich ist es eine Art Schema F, aber trotzdem tut man sich am Anfang schwer damit, bis man richtig ‘reinkommt.
Das Schema F
Eine rekursive Funktion muss immer mindestens einen Parameter haben, der sich bei jeder Iteration einer Schranke (z.B. 0) weiter nähert und die Funktion terminiert genau dann, wenn diese Schranke getroffen wird, d.h. alle rekursiven Aufrufe übergeben einen kleineren Wert für diesen Parameter. Diesen Parameter will ich ab jetzt als Laufparameter oder Iterationsparameter bezeichnen.
Der kursiv geschriebene Teil ist besonders wichtig, denn daran erkennen wir sofort, ob eine rekursive Funktion sich daran hält und wir wissen auch, wie wir dies selbst bewerkstelligen können.
Beispiel:
int fib( int n ) { ensure( n >= 0 ); if( n <= 1 ) { return n; else /* n >= 2 => n - 1, n - 2 >= 0 */ return fib( n - 1 ) + fib( n - 2 ); }Hier ist $$\text{n}$$ der Laufparameter und wie man sieht wird er bei jedem rekursiven Aufruf kleiner und nähert sich 0´ und bleibt auch immer $$ \ge 0 $$ (siehe Kommentar). Im Fall $$ n = 0 $$ wird die Rekursion beendet.
Bei einer Rekursion wird also die Ausführung auf Basisfälle zurückgeführt. Die Basisfälle der Fibonacci-Folge sind 0 und 1.
Frage: Wieso haben wir zwei Basisfälle?Antwort
Ich habe auch ensure verwendet um sicherzustellen, dass die Funktion nur mit gültigen Werten für n aufgerufen wird. Dadurch stelle ich sicher, dass sie immer terminiert.
Man kann hier schon unser Schema heraus folgern:
Schema F für Rekursionen
Besonders bei rekursive definierten Folgen in der Mathematik lässt sich diese Schema ganz von selbst anwenden´.
Als ein Beispiel können wir die Berechnung der folgenden Folge betrachten:
$$
a_n := \begin{cases}
0 & \text{ : } n=0 \\
a_{n-1} – 2n – 1& \text{ : } n \ge 1
\end{cases}
$$Die Signatur der Funktion in FJava ist offensichtlich $$\text{int a( int n )}$$.
Als Laufparameter kommt nur $$\text{n}$$ in Frage, einen anderen Parameter gibt es ja nicht.
Der Basisfall ist mit $$n=0$$ klar und die Rekursion erfolgt dann analog zur Definition und der Laufparameter wird mit $$\text{n-1}$$ auch kleiner, “geht also gegen 0” 🙂Nun zum Code:
int a( int n ) { ensure( n >= 0 ); if( n == 0 ) return 0; else return a( n - 1 ) + 2*n - 1; }Frage: Was berechnet diese Folge/Funktion?Antwort
Rekursive Funktionen über Sequenzen
Ist der Laufparameter eine Sequenz, dann betrachten wir die Länge der Sequenz implizit als Laufparameter und müssen als Basisfall eine Sequenz der Länge $$n_0$$ benutzen. Meistens wählt man $$n_0 := 0$$ und prüft dann einfach, ob die Sequenz leer ist.
Manchmal weiß man aber, dass nur nicht-leere Sequenzen übergeben werden können oder Sequenzen einer Mindestlänge, dann müssen wir die Länge der Sequenz abfragen.Beispiel:
<T> T last( Seq<T> seq ) { ensure( !isEmpty( seq ), "seq muss mindestens ein Element enthalten" ); if( isEmpty(rest( seq )) ) // ist äquivalent zu: length( seq ) == 1 return first(seq); return last(rest( seq )); }Man kann natürlich noch zusätzliche Basisfälle definieren – das kommt auf den Algorithmus an – aber man braucht mindestens einen Basisfall, damit die rekursive Funktion terminiert.´
Rückgabewerte im Basisfall
Oft ist der Basisfall eigentlich der Fall, in dem die Funktion nichts “tun” und der Wert des Ergebnisses vom Basisfall nicht beeinflusst werden soll.
Beispiele:
<T> int length( Seq<T> seq ) { if( isEmpty( seq ) ) return 0; return 1 + length( rest( seq ) ); } // gib jedes 2. Element zurück // wir fangen an bei 0 zu zählen, wie bei Indizes üblich <T> Seq<T> oddElements( Seq<T> seq ) { if( isEmpty( seq ) || isEmpty( rest( seq ) ) ) return emptySeq(); return concat( cons( first( rest( seq ) ) ), oddElements( rest( rest( seq ) ) ) ); } /* Testausgabe: oddElements( cons( 0,1,2,3,4,5 ) ) [1, 3, 5] */Was haben 0 und emptySeq() gemeinsam? Sie beeinflussen den Wert des Ergebnisses nicht.
Würden wir nicht addieren und konkatenieren, sondern im rekursiven Schritt multiplizieren, dann wäre unser Rückgabewert im Basisfall $$1$$.Mathematische Begründung:
Alle Rückgabewerte im Basisfall waren neutrale Elemente ihrer jeweiligen Algebraischen Struktur über der Sorte und dem Operator, auf der im rekursiven Schritt operiert wurde.
In den Beispielen waren dies die Gruppen $$\left( \mathbb{Z}, + \right)$$ und $$\left( \mathrm{Seq}, \circ \right)$$.Hieraus können wir auch noch eine Einsicht gewinnen:
Man kann keinen passenden Rückgabewert finden, der das Ergebnis nicht beeinflusst, wenn man zum Beispiel im rekursiven Schritt mit dem Rückgabewert addiert und multipliziert.Rekursiv Denken
An sich sind wir jetzt mit allem technischen durch – das einzige, das noch fehlt, sind ein paar Anmerkungen, die einem helfen können, rekursive Funktionen zu erstellen. Dies folgt jetzt.
Rekursives Programmieren ist die Mutter aller Divide & Conquer-Strategien: man spaltet das Problem immer wieder in gleichartige Teilprobleme, mit deren Lösung man das ursprüngliche Problem lösen kann, auf, bis man ein “Basisproblem”´ erhält, das leicht zu lösen ist´.
Die meisten Rekursionen, die wir bisher programmiert haben, waren sehr “unbalanciert”:
Bei Sequenzen zum Beispiel teilen wir die Sequenz oft in das erste Element und den Rest auf und bearbeiten dann das Element direkt und lassen in der Rekursion die Funktion das Problem für den Rest der Sequenz lösen und setzen dann alles wieder zusammen – siehe length oder so gut wie alle Funktionen, die wir bisher geschrieben haben.Wenn wir also rekursive Funktionen auf Sequenzen schreiben, müssen wir uns immer überlegen, wie wir mit der Lösung für ein Teilsequenz unserer Eingabesequenz und direktem Zugriff auf ein oder zwei Elemente, die Lösung des Problems für die ganze Sequenz finden.length( cons( "a","b","c","d" ) ) schematisch dargestellt
Dies ist der Grundgedanke der meisten Aufgaben, die wir behandeln.
Hilfsfunktionen
Oft hilft es auch, zusätzliche Hilfsfunktionen zu definieren, die einem die Arbeit erleichtern oder erst möglich machen, wenn die Signatur der Funktion selber nämlich keine Rekursion zulässt.
Als Beispiel die Tower-Funktion´:
// berechnet n^(n^(...)) n-mal Potenzieren (wobei ^ für's Potenzieren steht - deswegen heißt sie Turmfunktion) int tower( int n ) { ensure( n >= 0 ); return _tower( n, n ); } int _tower( int n, int k ) { ensure( k >= 0 ); if( k == 0 ) return 1; return pow( n, _tower( n, k - 1 ) ); } int pow( int a, int n ) { ensure( n >= 0 ); if( n == 0 ) return 1; return a * pow( a, n - 1 ); }Hier brauchen wir einige Hilfsfunktionen, wobei auffallen sollte, dass die eigentliche tower Funktion nur ein Stub (eng. für Stummel) ist und _tower die eigentliche Arbeit erledigt.
Also wenn man nicht wirklich weiter kommt:
Einfach schauen, ob man vielleicht Hilfsfunktionen geschickt benutzen kann.Soweit zur Theorie – im nächsten Post habe ich ziemlich viele Aufgaben gesammelt, die man ohne weiteres lösen kann ´.
Tags: Divide-and-Conquer Strategien, FJava, rekursive Funktionen
28 Nov 08 Aufgaben zu Rekursiven Funktionen
Hier noch einiges Übungsaufgaben, die jeder für sich lösen kannHinweis.
Operationen auf Sequenzen $$\mathrm{Seq} \langle T \rangle$$
- Wiederhole generische Funktionen und Sequenzen auf dem Merkblatt zu FJava.
- Schreibe die Funktionen <T> int length( Seq<T> seq ), <T> T last( Seq<T> seq ) ohne irgendwo nachzuschlagen.
- Entwickle eine Funktion <T> Seq<T> reverse( Seq<T> seq ), die eine Sequenz umdreht – aus [1,2,3,4] würde [4,3,2,1] werden.
- Entwickle eine Funktion <T> T _getNth( Seq<T> seq, int n ), die das n-te Element ($$n \ge 0$$) aus der Sequenz zurückgibt. Wir fangen an bei 0 zu zählen, also _getNth( [0,1,2,3,4], 3 ) = 3.
- Entwickle eine Funktion <T> T getNth( Seq<T> seq, int n ), die das n-te Element aus der Sequenz zurückgibt. Ist $$n < 0$$, so gebe das $$-n$$-te Element vom Ende der Sequenz zurück, also getNth( [4,3,2,1], -2 ) = 2.
- Schreibe eine Funktion <T> boolean isEqual( Seq<T> a, Seq<T> b ), die überprüft, ob alle Elemente in der Sequenz a gleich denen in b sind (in der gleichen Reihenfolge), also isEqual( [1,2,3], [1,2,3] ) = true, aber isEqual( [1,2,3], [3,2,1] ) = false und natürlich isEqual( [], [] ) = true und isEqual( [1,2], [1,2,3] ) = false.
Beachte hierbei, dass T auch String sein kann, also muss man vergleichen mit a.equals( b ) für a, b aus der Sorte T´.- Schreibe eine Funktion <T> boolean isPalindrome( Seq<T> a ), die überprüft, ob a ein Palindrom ist, d.h. a ist vorwärts und rückwärts gelesen gleich.
- Schreibe eine Funktion <T> boolean inSeq( T element, Seq<T> seq ), die überprüft, ob element in der Sequenz seq vorkommt.
Beachte hierbei, dass T auch String sein kann, also muss man vergleichen mit a.equals( b ) für a, b aus der Sorte T.
- Entwickle eine Funktion <T> int count( Seq<T> seq, T element ), die zurückgibt, wie oft element in der Sequenz seq vorkommt.
Beachte hierbei, dass T auch String sein kann, also muss man vergleichen mit a.equals( b ) für a, b aus der Sorte T.- Entwickle eine Funktion <T> int remove( Seq<T> seq, T element ), die alle Vorkommen von element aus seq löscht.
Sequenzen als Mengen
Mengen sind ein Spezialfall von Sequenzen, bei denen jedes Element höchstens einmal vorkommen darf und die Reihenfolge der Elemente egal ist (wenn man auf Gleichheit o.ä. prüfen will).
- Schreibe eine Funktion <T> boolean isSet( Seq<T> seq ), die zurückgibt, ob seq eine Menge ist, also ob jedes Element höchstens einmal in seq vorkommt.
- Schreibe eine Funktion <T> boolean inSet( T element, Seq<T> set ), die zurückgibt, ob element in set ist.´
- Schreibe eine Funktion <T> Seq<T> insertIntoSet( Seq<T> set, T element ), die element zur Menge set hinzufügt. Wenn für set gilt: isSet( set ) = true, dann soll dies auf für den Rückgabewert von insertIntoSet gelten.
- Schreibe analog eine Funktion removeFromSet.
- Entwickle Funktionen union und intersect die analog Mengen vereinen und schneiden.
- Entwickle eine Funktion <T> boolean isSubset( Seq<T> subSet, Seq<T> set ), die überprüft, ob $$ \mathbf{subSet} \subseteq \mathbf{set} $$ gilt.
- Entwickle eine Funktion <T> boolean isSetEqual( Seq<T> aSet, Seq<T> bSet ), die überprüft, ob die Mengen aSet und bSet gleich sind.
Wieso ist isSetEqual für Mengen weniger effizient als isEqual für Sequenzen?´- Entwickle eine Funktion <T> Seq<Seq<T>> powerSet( Seq<T> set ), welche die Potenzmenge der Menge set konstruiert. Für jedes Sequenz s aus dem Rückgabewert gilt also: isSet( s ) = true und isSubset( s, set ) = true.
Hinweis: Man entwickle zuerst eine Funktion <T> Seq<Seq<T>> setsWithoutOneElement( Seq<T> set ), welche alle Teilmengen von set zurückgibt, die ein Element weniger enthalten.´Operationen auf Sequenzen von Sequenzen´
- Entwickle eine Funktion <T> Seq<Seq<T>> expandFront( Seq<T> seq, Seq<T> choices ), die alle Sequenzen s zurückgibt, für die gilt: isEqual( rest( s ), seq ) = true und inSeq( first( s ), choices ) = true.´
- Entwickle eine analoge Funktion <T> Seq<Seq<T>> expandBack( Seq<T> seq, Seq<T> choices ), für die obigen Bedingungen für reverse( s ) statt s gelten. Wie sehen dann Nachbedingungen für expandBack aus?´
- Schreibe die Funktion <T> Seq<Seq<T>> expandAcyclicFront( Seq<T> seq, Seq<T> choices ), die nur Sequenzen s zurückgibt für die gilt: inSeq( first( s ), rest( s ) ) = false.
- Schreibe analog zu expandBack, die Funktion expandAcyclicBack.
- Entwickle eine Funktion <T> Seq<T> getNeighbors( Seq<Seq<T>> neighborSeq, T node ), die den Rest der Untersequenz zurückgibt, die als erstes Element node hat, oder die leere Sequenz, falls es keine solche Sequenz gibt, wobei jede Sequenz von neighborSeq ein anderes erstes Element besitzt, also wäre [[1,2],[1,2,3] keine gültige Sequenz.
Beispiel: getNeighbors( [[1,2,3], [2,1,4], [3,1]], 2 ) = [1, 4].Reflexive, Transitive Hüllen
Die reflexive, transitive Hülle $$ \rightarrow ^{\star} $$ über einer Menge $$\mathbf{G}$$ und einer Relation $$ \rightarrow : \mathbf{G} \times \mathbf{G} \rightarrow \mathbf{G}, \left( a, b \right) \mapsto a \rightarrow b $$ (gelesen: “a zeigt zu b”) ist folgendermaßen definiert´:
$$ \\\\
\forall a, b \in \mathbf{G}:\\
\begin{array}{lcl}
a \rightarrow ^ 0 b & :\Leftrightarrow & \begin{cases}
true & \text{ : } a = b \\
false & \text{ : } a \not = b\end{cases} \\\\
a \rightarrow ^ 1 b & : \Leftrightarrow & a \rightarrow b \\\\
a \rightarrow ^{n+1} b & : \Leftrightarrow & \exists x \in \mathbf{G}: a \rightarrow ^{n} x \land x \rightarrow b\\
\\
\\
a \rightarrow ^ {\star} b & : \Leftrightarrow & \exists n \in \mathbb{N}: a \rightarrow ^ n b
\end{array}
$$Wir können diese Konstruktion auch in FJava nachvollziehen, wenn wir die Relation in einer Adjanzentliste speichern, d.h. gilt:
$$
\mathbf{ G = \left \{ a, b, c, d, e \right \} }
$$
und
$$
\mathbf{
a \rightarrow b, a \rightarrow c, a \rightarrow d, b \rightarrow c, b \rightarrow d,
c \rightarrow a, d \rightarrow b, d \rightarrow e }
$$
so speichern wir das als:
$$\mathbf{seq := \left[\left[a, b, c, d \right], \left[b, c, d \right], \left[c, a \right], \left[d, b, e \right], \left[ e \right] \right]}$$
Sprich: Jedes Element kommt genau einmal als erstes Element in einer Untersequenz vor und der Rest der jeweiligen Untersequenz gibt die Elemente an, auf die das erste Element “zeigt”.
Dann können wir aus $$\mathbf{seq}$$ sowohl $$\mathbf{G}$$, als auch $$\rightarrow$$ bestimmen, da diese durch die Adjazenzliste eindeutig festgelegt sind.Außerdem können wir getNeighbors benutzen um aus solch einer Sequenz, alle Elemente zu finden, auf die ein bestimmes zeigt.
Im Folgenden sei mit neighborSeq immer die Adjazenzliste von $$ \rightarrow $$ bezeichnet.In dem Beispiel von oben: getNeighbors( seq, “a” ) = [ “b”, “c”, “d” ].
- Schreibe eine Funktion <T> Seq<Seq<T>> zeroHull( Seq<Seq<T>> neighborSeq ), die für die Relation, die durch die Adjazenzliste neighborSeq bestimmt ist, die Adjazenzliste aller Elemente bestimmt für $$ \rightarrow^0 $$.
Im Beispiel von oben wäre dies:
$$\mathbf{seq := \left[\left[a, a \right], \left[b, b \right], \left[c, c \right], \left[d, d\right], \left[ e, e \right] \right]}$$- Entwickle eine Funktion <T> Seq<T> squareHullForElement( Seq<Seq<T>> neighborSeq, T element ), die die Menge aller Elemente x enthält, die von element in zwei Schritten erreichbar sind, also: $$ \mathbf{ \exists y \in G: element \rightarrow y \rightarrow x }$$
- Entwickle eine Funktion <T> Seq<Seq<T>> squareHull( Seq<Seq<T>> neighborSeq ), die $$ \rightarrow ^2 $$ von neighborSeq zurückgibt.
- Entwickle eine Funktion <T> Seq<T> nthHull( Seq<Seq<T>> neighborSeq, int n ), die für $$ n \ge 0 $$ die n-te Hülle von $$\rightarrow$$ bestimmt, also $$ \rightarrow^n $$.
Hinweis:
Man schreibe zuerst eine Funktion <T> Seq<Seq<T>> concatenateRelation( Seq<Seq<T> neighborSeqN, Seq<Seq<T>> neighborSeq ), die zwei Relationen $$ \prec $$ und $$ \propto $$, die durch neighborSeqN bzw. neighborSeq beschrieben werden, auf $$ \mathbf{G}$$ hintereinanderausführt und die sich ergebende Relation $$ \sqsubset $$ als Adjanzenzliste zurückgibt, so dass für alle Teilsequenzen mit erstem Element e und restlichen Elementen x, gilt:
$$ \mathbf{ \exists y \in G: e \prec y \land y \propto x :\Leftrightarrow e \sqsubset x }$$.´- Schreibe eine Funktion <T> Seq<Seq<T>> transitiveHull( Seq<Seq<T>> neighborSeq ), die $$ \rightarrow ^{\star} $$ konstruiert. Die Funktion kann immer terminieren, da $$ \mathbf{G} $$ endlich ist.
Tags: Add new tag, Aufgaben, FJava, Mengen, Sequenzen, Transitive Hülle
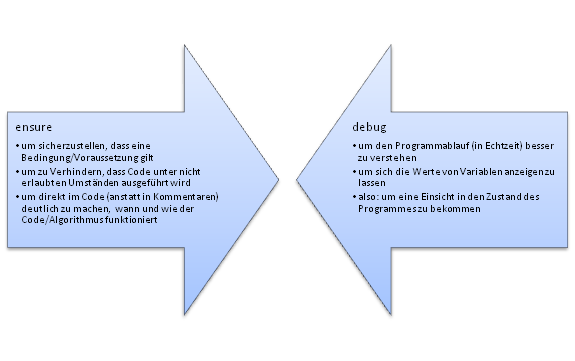
26 Nov 08 Ein paar Worte zu ensure und debug…
Das Merkblatt zu FJava sollte sich ja jeder ausdrucken und unters Kopfkissen legen und möglichst auch verstehen, aber ich möchte heute die Aufmerksamkeit auf die Sektion “Hilfsfunktionen” lenken.
Es werden zwei überaus nützliche Funktionen besprochen: ensure() und debug(), die außerdem für zwei klassische Hilfsmittel beim Programmieren stehen´.
debug()
debug kann man dazu verwenden um während der Ausführung etwas auszugeben. Der Name stammt vom Englischen to debug und wird in der Informatik verwendet um den Prozess der Fehlersuche und –korrektur in einem Computerprogramm, das nicht so läuft wie es soll, zu bezeichnen.
Die Ausgabe von Hilfsinformationen während das Programm läuft ist zugleich die älteste und die universellste Art Fehler zu suchen und den Ablauf des Programmes zu verfolgen. Praktisch alle Programmiersprachen und Systeme unterstützen eine Ausgabe von Daten zum Debuggen und der Programmierer ist frei in der Art und Weise, wann und wo er solche zusätzlichen Ausgaben hinzufügt.
Später im Verlauf der Vorlesung werden wir sicher noch weitere und mächtigere Mittel kennenlernen, die einem die Fehlersuche erleichtern, aber diese Mittel sind dann im Allgemeinen spezieller und aufwändiger.
Im Merkblatt wird im Beispiel kurz darauf eingegangen, wie man auch Variablen ausgibt, aber man kann auch beliebigen Ausrücken ausgeben.
debug( seq ); debug( "seq: " + seq ); debug( "first(seq): " + first(seq) );Falls der Code nicht so funktioniert, wie er soll, und man die Ursache durch Lesen des Codes findet, kann man einfach in die Funktion ein paar debug()-Aufrufe einstreuen und sich dann beim Ablauf anschauen, wie sich die Werte verändern – dies ist besonders bei rekursiven Funktionen nützlich.
ensure()
ensure ist ein anderes sehr mächtiges Werkzeug, das von der Idee auch bei der Programmverifikation eingesetzt wird. In den meisten Programmiersprachen wird die Anweisung mit assert bezeichnet, aber ensure ist vom Sinn genauso verständlich. ensure stellt sicher, dass eine Bedingung zur Laufzeit gilt, ansonsten wird eine Fehlermeldung ausgegeben.
Man kann ensure benutzen um einerseits seinen Code gegen “falsche” Aufrufe zu sichern, als Beispiel:
int sub(int a, int b) { ensure( b >= 0 ); if( b == 0 ) { return a; } else { return sub(a, b - 1) - 1; } }Ohne ensure könnte man sub(1, -1) aufrufen und das Programm würde in einer Endlosrekursion abstürzen ohne das man eine Ahnung hat wieso – in diesem Beispiel ist es noch einfach, aber spätestens bei größeren Funktionen, die sich gegenseitig aufrufen, kann’s unangenehm werden.
Man kann hier ensure benutzen um seinen Code gegen Missstände von außen abzusichern und gleichzeitig um deutlich zu machen, unter welchen Bedingungen man erwarten kann, dass die Funktion funktioniert 🙂
Ein Vorteil von ensure gegenüber einfachen Kommentaren im Quellcode ist, dass ensure eine Anweisung ist, die auch ausgeführt wird und deswegen auch immer aktuell ist – im Gegensatz zu Kommentaren, die schon mal veraltet sein können..
Auch bei ensure kann man wieder eine Fehlermeldung ausgeben, die man selbst wählen kann – mit den gleichen Mittel wie bei debug:
ensure( !isEmpty( seq ), "Sequenz darf nicht leer sein!" ); ensure( i > 5, "i > " + i ); ensure( first(seq) > 0, "first(seq): " + first(seq) + " > 0" );Man kann aber auch nur die Bedingung in ensure beschreiben und den Text weglassen:
ensure( true ); ensure( i > 0); ensure( first(seq) > 0 );Noch ein Beispiel zur “Programmverifikation”:
int sub(int a, int b) { ensure( b >= 0 ); if( b == 0 ) { return a; } else { final int result = sub(a, b - 1) - 1; ensure( result == a - b ); return result; } }Damit kann man bei jedem Aufruf sicherstellen, dass sub auch wirklich subtrahiert. Das ist natürlich kein Beweis für die Korrektheit der Funktion oder auch nur richtige Programmverifikation, aber es reicht auf jeden Fall aus um auch bei komplizierteren Funktionen zu testen, ob die Funktion sich in den Testfällen verhält, wie erwartet – weiterführend in dieser Richtung ist der Ansatz Design by Contract, bei dem bei jeder Funktion genau die Vor- und Nachbedingungen festgelegt werden (siehe oben die ensure-Bedingungen bei sub).
Also…
debug ist nützlich, wenn man das Programm besser verstehen will und/oder die Fehlerstelle einkreisen will. ensure kann man beim Entwickeln und allgemein nutzen um sicherzustellen, dass bestimmte Bedingungen zur Laufzeit erfüllt sind.
Die beiden Konzepte sind nicht orthogonal zu einander, aber man zumindest sagen, dass debug eher verwendet wird, wenn man Fehler sucht und zusätzliche Informationen braucht (also beim Testen und Debuggen) und ensure schon beim Schreiben des Codes eingesetzt wird um die Absichten des Autors einerseits und Beschränkungen des Codes andererseits deutlicher zu kennzeichnen.
Wie immer sind Kommentare und Feedback erwünscht 🙂
Grüße,
AndreasTags: assert, debug, debugging, design by contract, self-documenting code
22 Nov 08 Kontext-freie Grammatiken
Ein paar Worte zu Beginn..
Beim Korrigieren der Hausaufgaben ist mir aufgefallen, dass möglicherweise das Konzept der (kontext-freien) Grammatiken noch nicht zur Ganzheit verstanden wurde, bzw. die Ausdrucksmöglichkeiten noch nicht vollständig erfasst wurden. Natürlich gehört auch Übung und auch ein gewisses Maß an Intuition dazu um “gute” Grammatiken zu schreiben, aber im Folgenden möchte ich versuchen ein paar Hinweise und Tipps zu geben´.
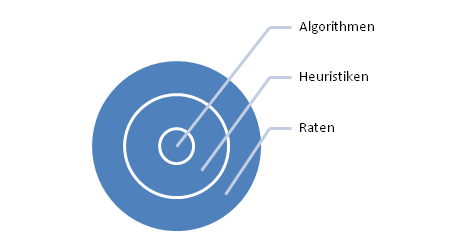
Zuerst möchte ich kurz auf das Konzept von Heuristiken im Software Engineering und in der Informatik allgemein eingehen´:
Heuristiken sind eine Verallgemeinerung von Algorithmen, dadurch gekennzeichnet, dass sie nicht so exakt und präzise formuliert sein müssen wie diese und auch nicht unbedingt immer funktionieren.
Heuristiken sind also “$$\pi$$ mal Daumen”-Ansätze und Regeln um oft gute Lösungen für ein Problem oder ähnliches zu finden, aber auch gleichzeitig Kompromisse.
Grammatiken
Betrachten wir nun ein paar “gute” Grammatiken und versuchen daraus Heuristiken abzuleiten.
Als erstes hätten wir die Grammatik aus der Hausaufgabe vom 2. Übungsblatt:
<bool_expr> ::= <bool_term> { “||” <bool_term> }*
<bool_term> ::= <bool_not> { “&&” <bool_not> }*
<bool_not> ::= [ ‘!’ ] <bool_factor>
<bool_factor> ::= <bool_const> | <bool_var> | ‘(‘ <bool_expr> ‘)’
<bool_const> ::= “true” | “false”
<bool_var> ::= ‘X’ | ‘Y’ | ‘Z’Schon aus dieser Grammatik kann man ein paar Beobachtungen herleiten, die einem helfen zu bestimmen, ob eine Grammatik “gut” ist oder nicht:

![length( [1,2,3,4] ) schematisch dargestellt](http://info1.blackhc.net/wp-content/uploads/2008/11/112808-1421-smartartdep21.png "112808-1421-smartartdep2.png")
- Die Grammatik ist eindeutig, d.h. es gibt nur genau einen Ableitungsbaum für jedes Wort der Sprache, welche die Grammatik darstellt.
- Jeder Operator kommt nur einmal in der Grammatik vor.
- Die Struktur der Grammatik ist einfach (sequentiell) und ähnelt dem Schema des Operatorvorranges´.
- Die geforderte Rekursion tritt nur an einer Stelle auf´.
Die Eindeutigkeit ist besonders wichtig, wenn wir daran denken, für wen solche Grammatiken gemeinhin gedacht sind: Computer/-programme. Programme oder Unterprogramme, die aus einem Ausdruck einen Ableitungsbaum konstruieren, heißen übrigens Parser´.
Eindeutigkeit ist also sicherlich eine Eigenschaft, die wünschenswert ist, wenn wir versuchen einen Ableitungsbaum zu erstellen. Erstellen wir einen Ableitungsbaum müssen wir ja rückwärts vorgehen und versuchen aus den einzelnen Grundelementen, die wir zur Verfügung haben, die Regeln abzuleiten, aus denen sie erzeugt wurden, und aus diesen dann ihre “Elternregeln”, usw. bis wir die Startregel erreichen.
Eindeutigkeit
Wie stellt man nun Eindeutigkeit sicher?
Wir können festlegen:
Zwei fortgeschrittene, verschiedene Ketten von Regelersetzungen (denn Grammatiken definieren ja nichts anderes als Termersetzungen, bei denen auf der rechten Seite immer nur genau ein Nicht-Terminal steht) enden in verschiedenen Wörtern der formalen Sprache (wenn sie überhaupt terminieren)´.
Oder anders gesagt:
Jedes Wort der formalen Sprache besitzt genau einen Ableitungsbaum (Äquivalenz durch Kontraposition).
Die Idee hier ist, dass man Grammatiken nicht nur benutzen kann, um aus vorgegebenen Ausdrücken Ableitungsbäume o.ä. zu konstruieren, sondern auch um neue Ausdrücke zu bauen (wieder analog zu den Konzepten von Termersetzungen, Grundtermen und Normalformen – Quizfrage: was sind hier die Analogien zu Grundformen und Normalformen?).
Als Beispiel (mit der Grammatik aus der Hausaufgabe):
<bool_expr> –> <bool_term> || <bool_term> –> <bool_not> || <bool_term> –> <bool_factor> || <bool_term> –> … –> X | Y
Aber zurück zum Thema: was ist nicht eindeutig?
Betrachten wir:
<startRegel> ::= <regelA> “||” <regelA> | <regelB> “||” <regelB>
.
.
.
Über diese Grammatik können wir keine Aussage bzgl. der Eindeutigkeit machen!
Der Fall, der uns interessiert ist folgender (als Beispiel):
<startRegel> ::= <regelA> | <regelB>
<regelA> ::= <regelC> “||” <regelC>
<regelB> ::= <regelC> “||” <regelC>
Man sieht leicht, dass wir es hier mit einer nicht eindeutigen Grammatik zu tun haben.
Aber genauso wenig eindeutig ist:
<startRegel> ::= <regelA> | <regelB>
<regelA> ::= <regelC> {“||” <regelC>} *
<regelB> ::= <regelC> {“||” <regelC>} +
Oder:
<regelA> ::= <regelA> + <regelA> | <regelA> − <regelA> | <regelA>
(Wieso?)
Worauf ich hinaus will: man kann wohl beliebig komplizierte/nicht-triviale Grammatiken bauen, die nicht eindeutig sind.
Wir kommen also mit dieser Eigenschaft nicht wirklich weiter, außer dass wir sagen können, dass sie wünschenswert ist. Als Heuristik ist sie aber insgesamt tauglich, weil wir sagen können, dass die Eindeutigkeit das große Ziel ist, wonach wir streben, wenn wir Grammatiken schreiben (mit den richtigen Techniken/Vorgehensweisen folgt sie aber fast automatisch).
Das heißt:

Es ist also gut zu versuchen, die Grammatik nicht mehrdeutig werden zu lassen, denn wenn man versucht eindeutige Grammatiken zu schreiben, erhält man automatisch auch einfache/knappe Grammatiken, was auf jeden Fall gut ist.
Semantische Eindeutigkeit
Betrachten wir also nun die 2. Eigenschaft: “Jeder Operator kommt nur einmal vor in der Grammatik vor.”
Die Beobachtung hierbei ist, dass es sinnvoll ist, jeden Operator nur einmal in einer Regel zu beschreiben, denn dann ist klar, dass zumindest dieser Operator eindeutig durch genau eine Regel gematcht (oder von ihr erzeugt) werden kann.
Wir können diese Beobachtung noch allgemeiner fassen, wenn wir uns kurz von dem Beispiel der booleschen Ausdrücke entfernen.
<ifexpr> ::= “if(” <cond> “)” <cmdblock> { “else” <cmdblock> }
<cmdblock> ::= <ifOrCmd> | [ ‘{‘ <ifOrCmd> {<ifOrCmd>}* ‘}’ ]
<ifOrCmd> ::= <command> | <ifexpr>
Hier haben wir es nicht mehr wirklich mit Operatoren zu tun, dafür aber mit if-Anweisungen. Man kann aber auch hier etwas feststellen:
jede Regel behandelt genau ein semantisches Konzept´.
Die Bezeichnung “semantisches Konzept” versucht auszudrücken, dass es sich um ein abstraktes Konzept handelt, das Teil der Sprache ist, und dass wir die Konzepte nach ihrer Semantik, also ihrer Bedeutung, unterscheiden.
Diese Feinheit ist insbesondere dann wichtig, wenn wir Sprachen betrachten, bei denen verschiedene Konzepte mit unterschiedlicher Bedeutung die gleiche Syntax haben.
Das ist jetzt nicht an den Haaren herbeigezogen, sondern es gibt sogar sehr viele Programmiersprachen, bei denen diese Unterscheidung wichtig ist. Als Beispiel sei hier nur Visual Basic angegeben.
In Visual Basic wird Variablen mit = ein Wert zugewiesen, andererseits wird in Bedingungen auch mit = überprüft, ob zwei Variablen den gleichen Wert haben. Natürlich ist es dann auch wahrscheinlich, dass es Probleme mit der Eindeutigkeit gibt; diese werden aber durch geschickte Wahl der Regeln oder Kontextbedingungen (siehe Vorlesung) umgangen.
Als Gegenbeispiel, dass diese Eigenschaft nicht immer erfüllt ist, betrachten wir dazu einmal einen Ausschnitt der Sprache Java aus den offiziellen Spezifikationen:
IfThenStatement:
if ( Expression ) StatementIfThenElseStatement:
if ( Expression ) StatementNoShortIf else StatementIfThenElseStatementNoShortIf:
if ( Expression ) StatementNoShortIf else StatementNoShortIfExpression:
“ein boolescher Ausdruck”Statement:
“eine beliebige weitere Anweisung (auch IfThenStatement und IfThenElseStatement)”StatementNoShortIf:
“eine beliebige weitere Anweisung (aber nur IfThenElseStatementNoShortIf und nicht IfThenStatement oder IfThenElseStatement)”
Ohne weiter auf den tieferliegenden Grund einzugehen (näheres dazu findet sich in den Spezifikationen) kann man aber feststellen, dass hier ein semantisches Konzept – die if-else-Anweisung – in mehr als einer Regel behandelt wird. D.h. die Beobachtung über die semantischen Konzepte ist auch höchstens eine Heuristik um eine gute Grammatik zu konstruieren und man muss auch daran denken, dass die Unterteilung nicht immer ganz klar ist.

Als Beleg dafür, dass sie trotzdem eine sehr nützliche Heuristik ist, sei auf die Übung 3 im 2. Übungsblatt verwiesen:
<table> ::= “<table” {<border>} “>” <headerRow> {<rows>}* “</table>”
<border> ::= “border=\”” <number> “\””
<headerRow> ::= “<tr>” {<headerData>}* “</tr>”
<headerData> ::= “<th>” <data> “</th>”
<rows> ::= “<tr>” {<rowData>}* “</tr>”
<rowData> ::= “<td>” <data> “</td>”
<data> ::= <table> | <number> | <text>
<number> ::= [ <ziffer> {<ziffer> | ‘0’}* ] | ‘0’
<ziffer> ::= ‘1’ | ‘2’ | ‘3’ | ‘4’ | ‘5’ | ‘6’ | ‘7’ | ‘8’ | ‘9’
<text> ::= {‘a’ | ‘b’ | ‘c’ | … | ‘z’ | ‘A’ | ‘B’ | … | ‘Z’}+
Struktur der Grammatik
Aus den bisher angegebenen Grammatiken kann man auch noch zwei weitere wichtige Heuristiken herleiten. Vorher schauen wir uns aber zuerst noch die 3. Eigenschaft vom Anfang an: “Die Struktur der Grammatik ist einfach (sequentiell) und ähnelt dem Schema des Operatorvorrang.”
Zuerst einmal: was ist damit gemeint?
Beide Teilaussagen der Eigenschaft werden hoffentlich klar(er), wenn man folgende Hierarchie anschaut:
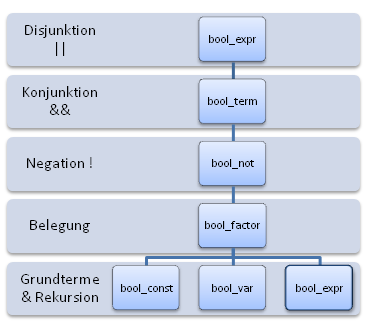
Erinnern wir uns jetzt, dass bei der Aufgabe folgender Operatorvorrang gelten soll (vom schwächeren zum stärker bindenden Operator hin):

Dann ist klar, dass Operatorvorrang und Regelhierarchie übereinstimmen und dies ist auch allgemein so:

Damit kann man schon recht leicht “nach Schema F” beliebige Rechenstrukturen mit beliebigen Operatorpräzedenzen/-vorrang abarbeiten und in eine Grammatik umwandeln, es stellt sich nur die Frage, wie es bei anderen Sprachkonstrukten aussieht.
Auf jeden Fall können wir noch ein anderes Ergebnis zusammenfassen, das bisher in allen Lösungen und Beispiele sichtbar war und auch so in der 3. Eigenschaft formuliert ist:

Es ist also sinnvoll, dass wir immer versuchen, die Regeln so einfach wie möglich zu formulieren, weil dies bei den Sprachen, die man normalerweise behandelt auch möglich ist. (Entweder das, oder es gibt gar keine Darstellung der Sprache als kontext-freie Grammatik – siehe dazu die Aufgabe 4 des 2. Übungsblattes mit der Frage, ob es eine BNF-Beschreibung der Sprache $$a^nb^nc^n$$ gibt.)
Insbesondere gibt uns das auch noch einen Hinweis, wie weit man die semantischen Konzepte versucht zu vereinfachen und zwar: so weit wie möglich. D.h. lieber mehr einfach strukturierte Regeln als eine äußerst komplexe.
Rekursion
Als letztes noch die 4. Beobachtung: “Die geforderte Rekursion tritt nur an einer Stelle auf.”. Aus den Beispielen kann man sehen, dass die Rekursion meistens erst sehr weit “unten” in der Hierarchie auftritt.
Dadurch, dass man die Rekursion möglichst weit nach unten “drückt”, also in die Richtung der Grundterme hin, kann man leicht sicherstellen, dass die Rekursion möglichst allgemein gilt und gleichzeitig erübrigt sich dadurch eine weitere Behandlung der gleichen Rekursion in der Hierarchie darüber.
In der Vorlesung wurde auch noch erwähnt, dass sich kontext-freie Grammatiken besonders zur Darstellung von Klammerstrukturen eignen, indem man rekursive Regeln aufstellt. Die Grammatiken der Tabellen und auch die geklammerten booleschen Ausdrücke oben sind gute Beispiele dafür und auch für das “Herunterdrücken” des Rekursionsfalles.
Hierzu noch ein kleines Beispiel für eine Grammatik, die alle gültigen Datensorten in FJava beschreibt:
<BasisTyp> ::= “int” | “float” | …
<WrapperTyp> ::= “Integer” | “Float” | …
<SequenzTyp> ::= “Seq” “<” <ObjektTyp> “>”<ObjektTyp> ::= <WrapperTyp> | <SequenzTyp>
<Typ> ::= <BasisTyp> | <ObjektTyp>
Wir fassen also zusammen:

Zusammenfassung und Ausblick
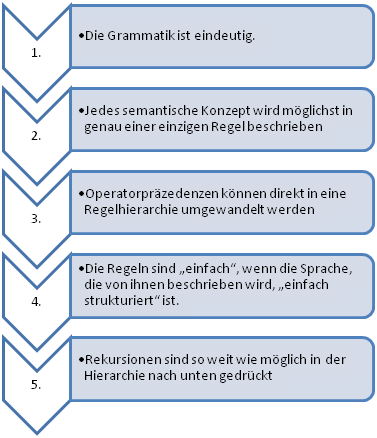
Damit haben wir fünf Heuristiken kennengelernt, die einem helfen können, bessere Grammatiken zu schreiben:
Zum Abschluss noch zwei zusätzliche Tipps, um sicherer im Umgang mit kontext-freien Grammatiken zu werden:
- Üben, üben, üben! 🙂
Wir haben Fjava in der Vorlesung nicht wirklich definiert, deswegen bietet es sich an für die Sprache selbst eine Grammatik zu entwerfen.
Es gibt aber auch Tools frei im Internet, mit denen man Parser aus einer BNF-ähnlichen Beschreibung einer Sprache erstellen kann. Es wäre also möglich die “Broy-Notation” aus der Vorlesung in Fjava umzuwandeln (mittels eines solchen Parsers und einfachen Textersetzungen). Wenn es dazu Fragen gibt, dann kann ich da gerne ein paar Links heraussuchen. - Es gibt viele Programmiersprachen und jede etwas ernsthaftere hat eine Spezifikation und alle beschreiben ihre Sprachen mittels einer Notation, die mehr oder weniger direkt auf der BNF-Notation basiert – man kann dort auch nach Inspirationen suchen 😉
Falls es noch Fragen gibt oder Feedback, dann schreibt mir eine Email oder nutzt die Kommentarfunktion 🙂´
Tags: BNF, Grammatik, Heuristik, Java
14 Nov 08 Wann benutzt man $$\equiv$$ und wann $$\Leftrightarrow$$?
Bei der Korrektur der Hausaufgaben ist mir aufgefallen, dass viele $$\Leftrightarrow$$ statt $$\equiv$$ benutzen, wenn sie die logische Terme umformen. Die Musterlösungen verwenden immer $$\equiv$$, wie vielleicht aufgefallen ist, und ich habe das Verwenden von $$\Leftrightarrow$$ in der letzten Hausaufgabe auch immer angestrichen (aber keine Punkte abgezogen).
Deshalb ist es sinnvoll, einen kleinen Überblick zu geben, für den in der Übung heute keine Zeit war:
Also wann benutzt man was?
Wenn wir mit algebraischen Gleichungen der Form
$$ x^2 = 9 $$
arbeiten, benutzen wir $$\Leftrightarrow$$ um auszudrücken, dass bestimmte Gleichungen äquivalent sind, also unter den bekannten Umformungen semantisch gleich sind (u.a. für die Variable $$x$$). Als Beispiel:
$$\left.\begin{array}{cc}
& x^2 = 9 \\
\Leftrightarrow & \left|x \right| = 3 \end{array}\right.$$
Während also $$+$$, $$-$$, $$*$$, etc. Operatoren sind auf die wir Umformungen anwenden, benutzen wir $$\Leftrightarrow$$, aber auch die anderen logischen Operatoren, als Metaoperatoren (meta: griech. ‘über’) um über die Gleichungen Aussagen zu machen (also dass sie äquivalent sind zum Beispiel).
Ein anderer Metaoperator wäre zum Beispiel $$\Rightarrow$$ bei algebraischen Gleichungen:
$$\left.\begin{array}{cc}
& x = 3 \\
\Rightarrow& x^2 = 9 \end{array}\right.$$
In der Aussagen- und Prädikatenlogik operieren wir aber auf Aussage (bzw. Aussageformen) und dieses Mal sind die Metaoperatoren oben unsere Operatoren ($$\Leftrightarrow$$, $$\Rightarrow$$, etc.), d.h. wir brauchen andere Metaoperatoren um über die Aussagenlogik diskutieren zu können. $$\equiv$$ ist ein solcher Metaoperator, $$\not \equiv$$ auch und $$\models$$ ein anderer, den wir vielleicht später kennen lernen werden.
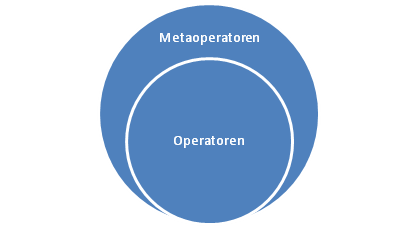
Wir benutzen $$\equiv$$ um etwas über die Gleichheit von Ausdrücken/Gleichungen der Aussagenlogik zu sagen.
$$\left.\begin{array}{ccccc}
& x^2 = 9 & & & \lnot a \Leftrightarrow \lnot b \\
\Leftrightarrow & \left|x \right| = 3 & \;\;\;\;\;\;\;\;\;\; & \equiv & a \Leftrightarrow b \end{array}\right.$$
In dieser Gegenüberstellung sieht man, wie $$\Leftrightarrow$$ rechts als normaler Operator auftritt und $$\equiv$$ als Metaoperator benutzt wird.
Tags: Äquivalenz, Metaoperatoren, Operatoren
14 Nov 08 Tutoraufgabe 4d)
Hallo,
anbei die Lösung für die Teilaufgabe d). Die Teilaufgabe c) ergibt ist nur eine Vereinfachung davon. Die Idee für die c) kann man leicht sehen, wenn man die Lösung auf einer der leeren Karten laufen lässt. Aber bevor Ihr es laufen lasst, versucht selbst daraufzukommen.
BTW was ich jetzt noch gehört habe, ist die Aufgabe, die letzte ihrer Art für’s erste, deswegen ist es auch nicht so schlimm, das wir nicht wirklich damit durch gekommen sind. Aber es lohnt sich trotzdem noch ein wenig damit herumzuspielen um besser mit if-else-Konstrukten vertraut zu werden.
Grüße,
Andreas
Tags: Übungsblatt 4
14 Nov 08 Dieser Blog
Dieser Blog ist als Auffanglager für Interessantes und Zusätzliches und auch Weiterführendes (falls ich Zeit finde) zu der Tutorübung gedacht, die ich am Freitag halte.
Kommentare und Diskussionen sind immer erwünscht, und falls nötig, werde ich auch noch zusätzliche Plugins installieren um ein besseres Diskutieren zu ermöglichen.
Grüße,
Andreas

